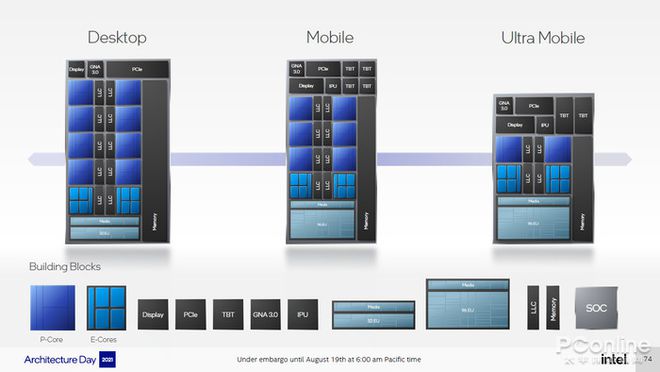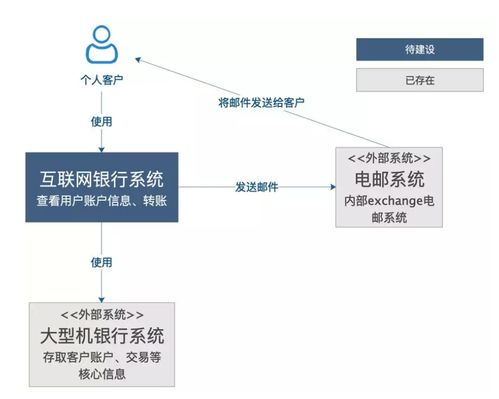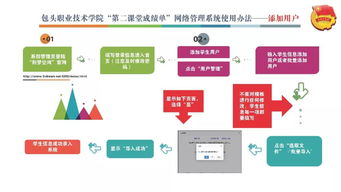
引言
在當今信息爆炸的時代,知識圖譜作為一種結構化的語義知識庫,已成為人工智能、大數據分析和智能應用的核心技術之一。其本質是通過圖結構對實體、概念及其關系進行建模,實現知識的有效組織和智能推理。圖數據庫憑借其天然的圖數據存儲和查詢優勢,成為構建和存儲大規模知識圖譜的理想技術載體。本文將深入探討基于圖數據庫的知識圖譜存儲技術,并結合計算機軟硬件技術開發的實踐,闡述其實現路徑與應用價值。
一、 圖數據庫:知識圖譜的天然存儲基石
與傳統的關系型數據庫 或 NoSQL數據庫 相比,圖數據庫在處理高度互聯、關系復雜的數據時展現出獨特優勢。其核心技術特點包括:
- 圖模型原生支持:圖數據庫以“節點”(代表實體或概念)、“邊”(代表關系)和“屬性”作為基本數據模型,這與知識圖譜的“實體-關系-屬性”三元組結構完美契合,避免了關系型數據庫中多表連接帶來的性能瓶頸。
- 高效的關系查詢:圖查詢語言(如 Cypher、Gremlin)支持直觀的圖模式匹配和路徑查詢,能夠輕松實現多跳查詢、最短路徑發現、社區發現等復雜操作,這對于知識推理和關聯分析至關重要。
- 卓越的擴展性:優秀的圖數據庫(如 Neo4j、JanusGraph、Nebula Graph)能夠通過分布式架構,支持海量節點和邊的存儲與查詢,滿足企業級知識圖譜的規模要求。
因此,選擇圖數據庫作為底層存儲引擎,是實現高性能、可擴展知識圖譜系統的首要技術決策。
二、 知識圖譜存儲的核心技術棧與實踐
一個完整的知識圖譜存儲系統,遠不止于選擇一個圖數據庫。它涉及從數據到應用的全鏈路技術開發實踐。
1. 存儲架構設計與選型
- 選型考量:根據數據規模(千萬級、億級、百億級)、查詢模式(OLTP 還是 OLAP)、一致性要求、成本預算等因素,在原生圖數據庫(如 Neo4j)、基于分布式存儲的圖數據庫(如 JanusGraph 基于 HBase/Cassandra)或新興的高性能圖數據庫(如 Nebula Graph)之間做出選擇。
- 硬件考量:圖數據庫通常是內存和IO密集型應用。實踐表明,配置大內存(用于緩存熱數據和索引)、高速NVMe SSD(用于快速讀寫圖數據文件)以及高性能網絡(在分布式部署中)能顯著提升系統整體性能。
2. 數據建模與模式設計
- 模式定義:需要精心設計節點標簽(Label)、關系類型(Type)和屬性(Property)的Schema。良好的模式設計是保證查詢效率和知識一致性的基礎。
- 索引策略:針對高頻查詢的屬性(如人名、產品ID)建立索引,可以加速節點和邊的查找。圖數據庫通常支持屬性索引和全文索引。
3. 數據導入與實時更新
- 批量導入:利用數據庫提供的批量導入工具(如 Neo4j 的 neo4j-admin import,Nebula Graph 的 Spark Connector),將來自結構化數據庫、半結構化JSON或經過信息抽取得到的RDF/N-Triples數據高效導入圖庫。此過程往往需要與ETL流程和計算框架(如Apache Spark)結合。
- 增量更新:設計事務性寫入流程,支持知識的實時增、刪、改。這需要處理好數據一致性與并發控制,是系統開發中的關鍵環節。
4. 查詢接口與性能優化
- API開發:基于圖數據庫的驅動(如 Neo4j Driver),開發面向業務應用的RESTful API或GraphQL接口,封裝復雜的圖查詢邏輯。
- 性能調優:通過分析查詢執行計劃、優化Cypher/Gremlin語句、調整數據庫配置參數(如內存分配、緩存大小)、設計合理的分片策略(分布式環境下)等手段,持續提升查詢響應速度。
5. 與上層應用的集成
- 圖計算與分析:將圖數據庫作為基礎存儲,與圖計算框架(如 Apache Spark GraphX、Neo4j Graph Data Science Library)集成,進行大規模的圖算法分析(如PageRank、社區發現、節點相似度計算),挖掘深層知識。
- 與AI模型結合:知識圖譜可為機器學習模型提供特征(如圖嵌入),也可利用模型進行知識補全和關系預測,形成“圖+AI”的閉環。這需要設計穩定高效的數據交換管道。
三、 計算機軟硬件技術開發的協同支撐
知識圖譜存儲系統的落地,強烈依賴于底層軟硬件技術的成熟與協同。
- 軟件層面:
- 操作系統與容器化:在Linux系統上進行部署和優化,并利用Docker、Kubernetes等容器化技術實現服務的快速部署、彈性伸縮和高效運維。
- 中間件與監控:集成消息隊列(如Kafka)處理數據流,使用Prometheus、Grafana等工具對圖數據庫集群的CPU、內存、磁盤IO、查詢延遲等關鍵指標進行全方位監控和告警。
- 開發框架與工具鏈:采用現代化的微服務開發框架(如Spring Cloud),并結合CI/CD工具鏈,實現系統的敏捷開發和持續集成部署。
- 硬件層面:
- 計算與存儲分離架構:在云原生環境下,采用計算與存儲分離的架構成為趨勢。計算節點(運行圖數據庫進程)可以獨立于存儲節點(如分布式塊存儲或對象存儲)進行伸縮,以獲得更好的成本效益和靈活性。
- 異構計算探索:針對圖遍歷和計算密集型圖算法,可以探索利用GPU或FPGA等異構計算硬件進行加速,這是前沿的性能優化方向。
四、 實踐案例與挑戰展望
在實踐中,基于圖數據庫的知識圖譜已廣泛應用于金融風控(識別欺詐團伙)、社交網絡分析、推薦系統(商品/內容關聯推薦)、生物信息學(蛋白質相互作用網絡)、IT運維(故障傳播鏈路分析)等領域。
挑戰依然存在:
- 超大規模圖的管理:當圖譜擴展到千億邊級別時,分布式圖數據庫的查詢延遲和數據一致性問題仍需進一步優化。
- 多模態知識融合:如何高效存儲和查詢文本、圖像等非結構化數據中抽取的知識,并與結構化知識圖譜融合,是未來的研究方向。
- 硬件與軟件的深度協同:為圖計算和存儲設計專用硬件或指令集,實現更極致的性能,是學術界和工業界共同關注的課題。
###
基于圖數據庫的知識圖譜存儲技術,正處于從技術探索走向大規模產業應用的關鍵階段。它將數據庫技術、圖論、分布式系統與具體的計算機軟硬件開發實踐深度融合。成功的系統不僅依賴于對圖數據庫特性的深刻理解,更依賴于從數據建模、系統架構到軟硬件協同優化的全鏈路工程能力。隨著技術的不斷演進,它必將為構建更智能、更互聯的數字世界提供堅實的數據基礎設施。