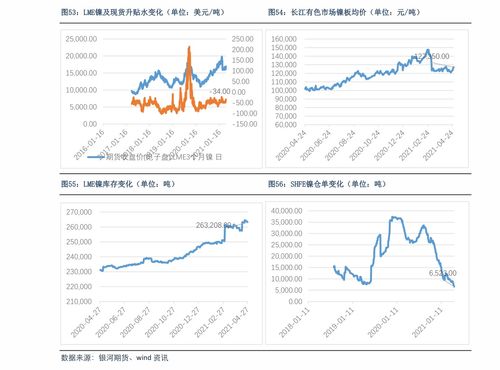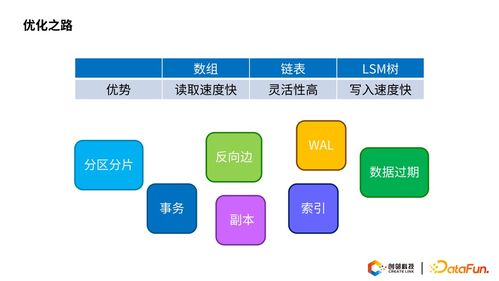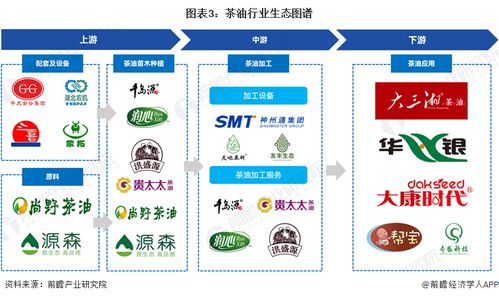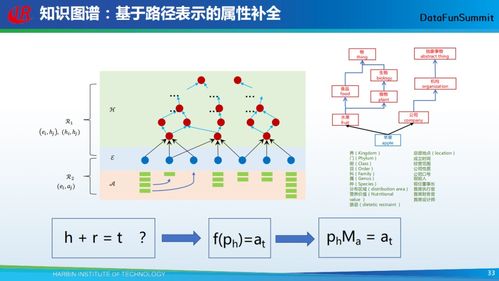
在信息爆炸的時代,如何從海量文本中快速提取核心內容,已成為個人與企業高效決策的關鍵。文本自動摘要技術,作為自然語言處理領域的重要分支,正憑借其強大的信息凝練能力,悄然改變著我們的信息處理方式。我們有幸采訪了北京大學計算機科學技術研究所的萬小軍教授,深入探討了該技術的發展現狀、核心挑戰及其對計算機軟硬件技術開發帶來的深遠影響。
萬小軍教授指出,文本自動摘要技術主要分為兩大范式:抽取式摘要和生成式摘要。抽取式摘要如同一位嫻熟的編輯,從原文中直接選取重要的句子或片段進行重組,保留了原文的準確性與客觀性,技術相對成熟,已廣泛應用于新聞簡報、報告生成等場景。而生成式摘要則更像一位理解透徹的作家,在深度理解原文語義的基礎上,運用自然語言生成技術,用自己的話重新表述核心內容。這種方式靈活性更高,能生成更流暢、連貫的摘要,但對模型的理解與生成能力要求也更為嚴苛,是當前研究與產業應用的前沿焦點。
技術的飛躍離不開底層計算機軟硬件的強力支撐。萬教授強調,特別是近年來深度學習,尤其是基于Transformer架構的大規模預訓練語言模型的興起,極大地推動了生成式摘要的性能突破。這些模型參數規模龐大,訓練與推理過程需要消耗巨大的計算資源。這直接驅動了高性能計算硬件(如GPU、TPU等)的持續創新與優化,以及分布式計算框架、高效模型壓縮與推理引擎等軟件技術的快速發展。可以說,文本摘要技術的演進,與計算芯片的算力提升、內存帶寬的擴大以及軟件算法的效率優化形成了緊密的協同進化關系。
挑戰依然存在。萬小軍教授談到,如何讓模型具備真正的深度理解與推理能力,而不僅僅是模式匹配;如何確保生成內容的忠實性、減少事實性錯誤或“幻覺”生成;如何適應不同領域、不同風格文本的個性化摘要需求,都是當前亟待攻克的研究難題。隨著多模態信息的普及,融合文本、圖像、音頻信息的跨模態自動摘要,也將成為未來的重要方向,這對異構計算和跨模態表示學習提出了新的軟硬件要求。
在應用層面,該技術已滲透至多個行業。從媒體行業的智能快訊生成,到金融領域的財報與研報分析;從法律文書的要點提煉,到醫療健康領域的病歷信息;再到為每位用戶定制的個性化信息推送,自動摘要技術正成為提升信息處理效率的核心工具。它不僅節省了人類處理信息的時間成本,更在某種程度上延展了我們的認知邊界。
萬小軍教授認為,文本自動摘要技術將朝著更智能、更可控、更專業的方向發展。它需要與知識圖譜、因果推理等結合,變得更“懂行”;也需要設計更友好的人機交互機制,讓用戶能夠引導摘要的生成過程。而這整個過程,將持續驅動從專用AI芯片、云計算平臺到邊緣計算設備的全棧軟硬件技術生態的迭代與創新。
總而言之,在萬小軍教授等科研工作者的不懈推動下,文本自動摘要技術正逐步從實驗室走向廣闊的應用天地。它不僅是自然語言處理皇冠上的一顆明珠,更是連接前沿人工智能研究與現實世界需求的一座橋梁,其發展必將深刻重塑我們未來獲取與利用信息的方式。